
NTech Predict とは
企業のDX推進を支援するAIデータ活用ツールです。
3つの機能「予知保全」「因果探索」「時系列予測」でAIがアシストし、業務を効率化します。
誰でも簡単に扱える操作性で属人化を解消し、組織のパフォーマンスを向上させることが可能です。

スキル不要!
ボタンひとつで簡単分析

データサイエンティストが運用をサポート

予測に必要な情報を自動生成 自動特徴量エンジニアリング

説明可能AI「XAI」が判断根拠を
提示するから安心

データの不備を自動修正する
データクレンジング

無理なく導入しやすい
価格体系





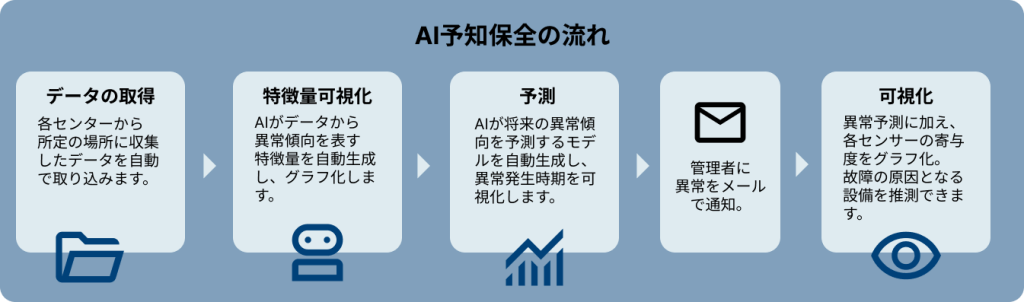
AIが毎日のデータから異常が起こるタイミングを予測し、メールで通知。
データの寄与度も表示するため、故障の原因となる箇所を推測することができます。
故障が発生する前に修理することで、メンテナンスコスト削減・ダウンタイム短縮を実現し、業務を効率化します。
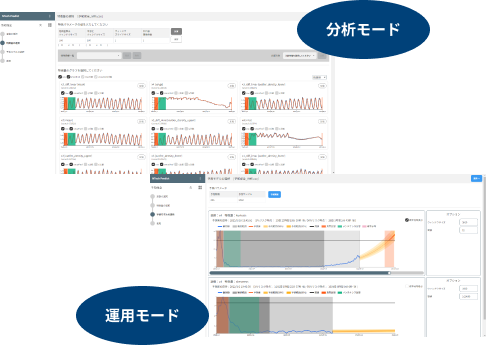
■分析モード
観測データでは目視できない異常傾向をAIが解析し、特徴量を自動生成。
故障に影響する特徴量を選択します。
■運用モード
分析モードで選択した特徴量から将来を予測するモデルを生成し、日々の観測データから異常の予兆を自動検知・通知します。

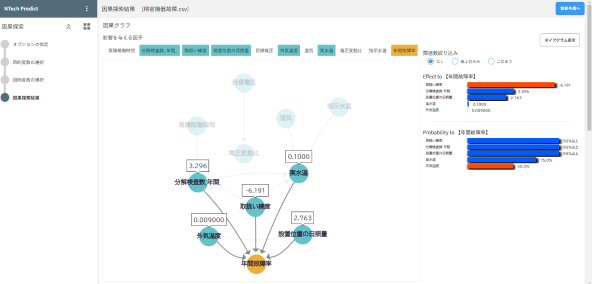
目には見えないデータ間の因果関係を可視化。
関係の方向・強さをチャート図で表示します。
分析には滋賀大学データサイエンス学部 清水昌平教授の「統計的因果探索(LiNGAMモデル)」を適用。※1
チャート図
線形性や非線形性を見て、信頼性を確認することが可能
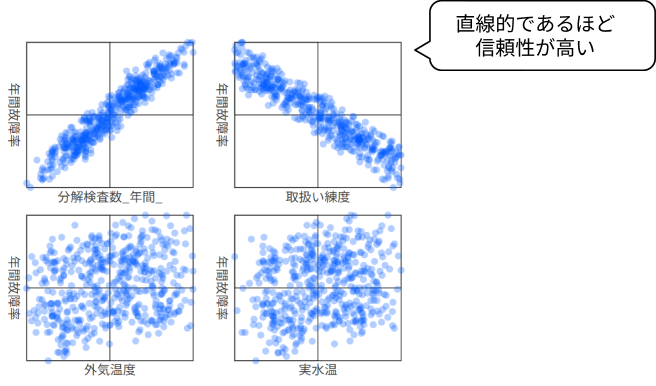
散布図
※1
- S. Shimizu, P. O. Hoyer, A. Hyvärinen, and A. Kerminen. A linear non-gaussian acyclic model for causal discovery. Journal of Machine Learning Research, 7: 2003–2030, 2006.
- A. Hyvärinen, K. Zhang, S. Shimizu, and P. O. Hoyer. Estimation of a structural vector autoregression model using non-Gaussianity. Journal of Machine Learning Research, 11: 1709-1731, 2010.

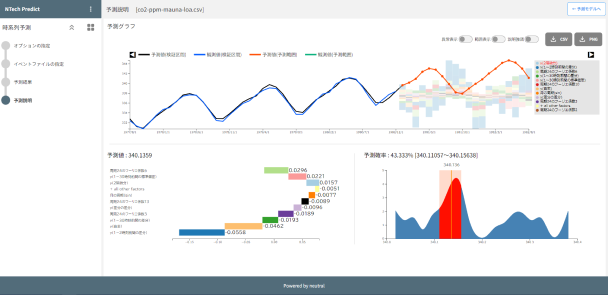
時間と共に変化するデータの未来をAIが自動予測。
需要予測や売上予測、消費電力予測、収穫量予測などに活用できます。
データサイエンティストの作業を自動化し、無駄のない最適な計画策定 をアシスト。
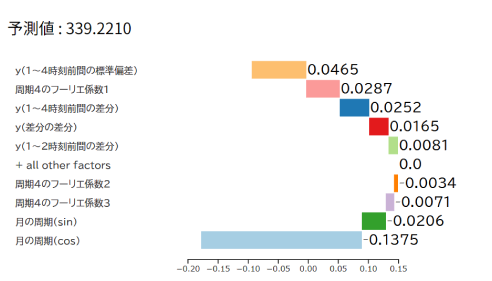
「XAI」が各データの影響度も表示するため、予測結果に作用している要因を知ることができます。
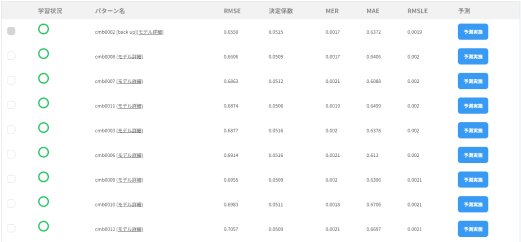
予測モデルとしての有効性を確認できます。
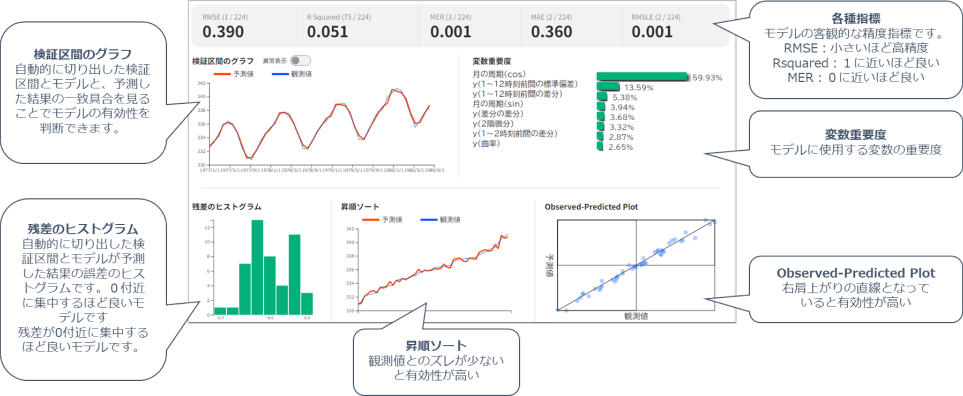

説明可能なAI「XAI」※がブラックボックス化を防ぎ、予測根拠を表示します。


※「XAI」(Explainable AI)とは
答えを出すだけのAIから、答えを信頼するための根拠を提示する技術です。「説明可能なAI」とも呼ばれています。
人間が与えた情報に不確実性がある中で、AIの答えが正確になることはありえません。
そのため、AIの答えを信じるべきかどうか、最終的な意思決定は人間が行うことが大切です。
※「自動特徴量エンジニアリング」とは
データから予測に必要な情報を抽出し、説明変数として自動的に追加していく技術です。
例えば日時のデータからは[午前・午後]の情報が得られます。月日のデータからは[四季]や[曜日(休日、祝日)]の情報を得ることができます。

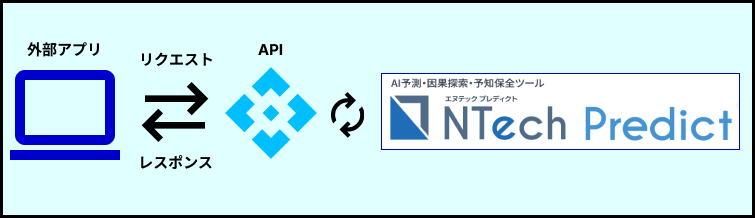
外部アプリ連携で機能拡張
APIオプション
外部アプリケーションから動作させるAPI機能(RESTful API)です。APIを活用することで、お使いのアプリと連携することができます。
定期的な分析操作の自動化、分析データに基づく独自レポートの作成など、現場に合わせた自由度の高い運用が可能になります。
技術検証を1からサポート
PoCサービス
分析結果を検証したいお客様向けの、PoC伴走型支援サービスです。
環境や要件に合わせて最適なプランを提案し、経験豊富なデータサイエンティストが計画策定から成果判定まで一貫して支援します。
①データ検証サポート
PoCに必要な[課題整理からゴール・仮説設定、課題解決案・計画の策定]をデータサイエンティストが支援します。
②実証検証サポート
課題解決案・計画に沿って、[仮説の実証検証、評価・成果判定]のプロセスをお客様と共に実施します。
データサイエンティストがお困り事を解決
製品サポート
操作方法やデータ分析上の不明点など運用に関する質問に、システムエンジニアおよびデータサイエンティストがメールで対応。
豊富な経験で培ったノウハウを活かし、お客様の課題を解決します。
そのほか、不具合修正パッチやバージョンアップ時の最新モジュールを提供。

| 機能 | |
|---|---|
| 入力データ | テーブル型CSVファイル |
| 自動データクレンジング | |
| 入力データの基本統計可視化 | |
| 時系列予測 | 自動特徴量付与 |
| 特徴量組み合わせ最良探索 | |
| 最良モデル探索 | |
| 予測値への寄与因子可視化 | |
| 予測値の確率密度推定→確率可視化 | |
| 長期予測(未観測未来)の特徴量の頻度推定 | |
| 時系列のグローバルな異常とローカルな異常の両方を検出 | |
| 外的イベント(休日等)対応(休日や特別なイベントのモデリング) | |
| 時系列予測結果のCSVダウンロード | |
| 予知保全 | 長期時系列異常予測 |
| 長期時系列異常予測の異常発生確率密度推定 | |
| 長期時系列異常予測の期間内異常発生確率の可視化 | |
| 因果探索 | 混在データの自動データ分離(クラスタリング) |
| クラスタリングアルゴリズム選択 | |
| クラスタリングアルゴリズム選択 | |
| 因果関係の強度推定と可視化 | |
| 因果関係の因果方向妥当性推定(確からしさの確率可視化) | |
| 離散値対応 | |
| 時系列因果探索対応 | |
| 因果探索結果(隣接行列)のCSVダウンロード | |
| 可視化 | インタラクティブプロット可視化 |
| インフォグラフィックス | |
| オプション | API提供 |

スペック
| OS | Windows10/11 |
| 推奨スペック(CPU/メモリ) | Intel Core i7-9700 3Ghz, 16GB以上 |
| HDD/SSD空き容量 | 512GB以上 |
| ブラウザ | Google Chrome, Microsoft Edge |
端末要件
- Windows1021H以降
- CPU仮想化が有効であること。計算速度はCPU性能に依存するため、計算速度の速いほうが処理が速くなります。
- ユーザディレクトリ以下の空き容量が1TB以上あることを推奨します。
- ストレージは、SSDを推奨します。
※ユーザディレクトリ以下とは
「%USERPROFILE%」にインストールされるため、インストールユーザしか使用できません。
ユーザディレクトリ以外での動作はサポート未対応となっています。

購入タイプ
お客様のご利用機能に応じ、以下の購入タイプからお選びいただけます。
| 購入タイプ / 機能 | 予知保全 | 因果探索 | 時系列予測 |
|---|---|---|---|
| スタンダード | 〇 | 〇 | 〇 |
| ライト | × | 〇 | 〇 |
ライセンス体系・価格(税別)
| 購入タイプ / ライセンス | 永続ライセンス版 | サブスクリプションライセンス版 (年額) |
|---|---|---|
| スタンダード | ¥3,000,000 | ¥500,000 |
| ライト | ¥2,000,000 | ¥320,000 |
| API機能(オプション) | ¥600,000 | ¥100,000 |
※永続ライセンス版の場合、製品・オプション共に、次年度以降は年間保守料金(製品価格の10%)が必要です。
※使用するPC1台あたりにライセンスが必要となります。
※PoC支援サービスの価格につきましてはお問い合わせください。
製品に関するお問い合わせ
お問い合わせフォームでご連絡ください。